[Date Prev][Date Next][Thread Prev][Thread Next][Date Index][Thread Index]
Re: [HTCondor-users] Consistency problems between schedd(s) view and CM?
- Date: Wed, 3 Dec 2025 12:04:11 +0100
- From: Jeff Templon <templon@xxxxxxxxx>
- Subject: Re: [HTCondor-users] Consistency problems between schedd(s) view and CM?
Hi
Thanks for your answer, Christoph. I can follow your words and agree with them generally, except that âa little bitâ is not the right description - see the attached plot. There are moments where the discrepancy (amount by which the sum rule is violated) approaches 15%.
Maybe others will chime in, Iâm inclined to view the CM as holy, albeit it possibly not entirely up-to-date, as it seems to always be self consistent.
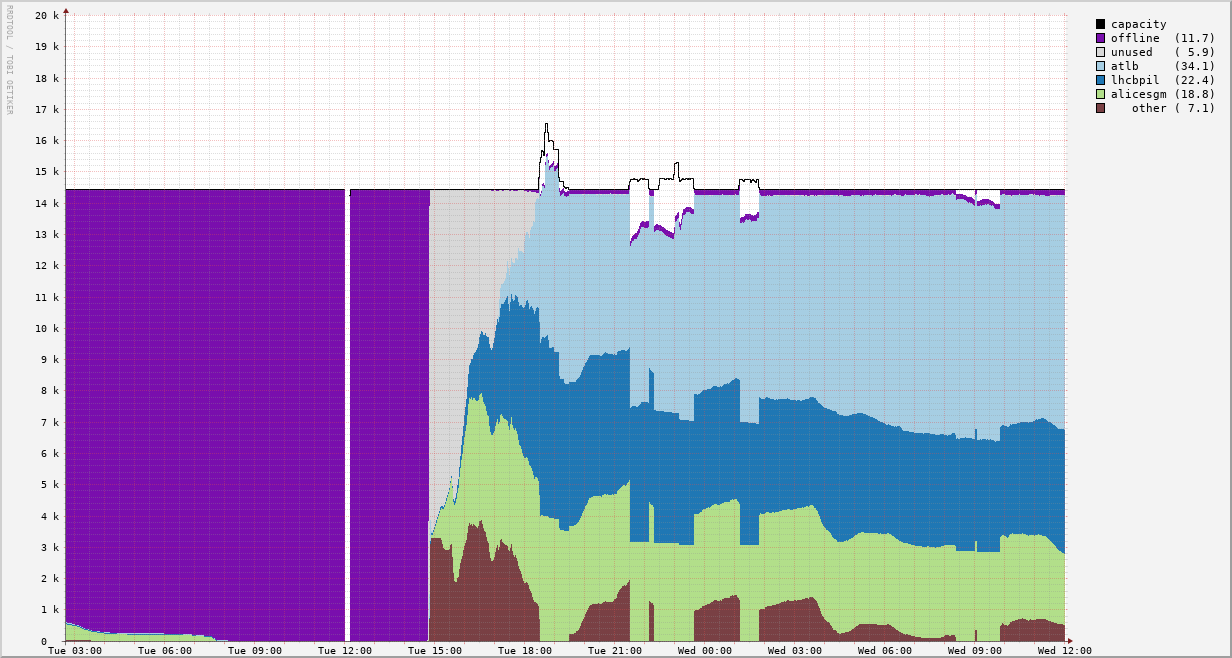
In the plot, the black line should be flat at the actual number of cores, and the colors should sum up to the black line (so no white gaps).
JT
> On 3 Dec 2025, at 10:59, Beyer, Christoph <christoph.beyer@xxxxxxx> wrote:
>
> Hi Jeff,
>
> I did not check that in our pool deliberately but I recognized that especially in busy situations HTC acts like most distributed systems and there is a little bit of diff in the state-db's depending on which entity you query.
>
> From my experience it equals out pretty soon and the most relevant information is depending on what you are aiming for either the AP or the CM.
>
> You can probably tune a little bit the collector and negotiator to very frequent and short cycles and minimize the claim lifetime etc. did some of that to speed up the interactive part of the NAF but for classic batch I would rather focus on the reliable scale out and live with some moments of relative uncertainty about a very small fraction of the pools resources.
>
> Best
> christoph
>
> --
> Christoph Beyer
> DESY Hamburg
> IT-Department
>
> Notkestr. 85
> Building 02b, Room 009
> 22607 Hamburg
>
> phone:+49-(0)40-8998-2317
> mail: christoph.beyer@xxxxxxx
>
> ----- UrsprÃngliche Mail -----
> Von: "Jeff Templon" <templon@xxxxxxxxx>
> An: "HTCondor-Users Mail List" <htcondor-users@xxxxxxxxxxx>
> Gesendet: Mittwoch, 3. Dezember 2025 10:28:14
> Betreff: Re: [HTCondor-users] Consistency problems between schedd(s) view and CM?
>
> Hi,
>
> I see I left some material hanging after an edit and apparently cut out some other info without putting it back in:
>
> The âsum ruleâ is : collect information from the schedds about running jobs and add up all the cores from those
> Collect information from the CM about free slots, offline slots, and slots blocked by the defrag daemon
> Add all the above: should equal the total capacity
>
> The âalternate viewâ is to collect the running job information from the CM (dynamic slots) instead of the schedds.
>
> Maybe that was clear, but I wasnât happy with how it was described when I re-read it.
>
> JT
>
>
>> On 3 Dec 2025, at 10:16, Jeff Templon <templon@xxxxxxxxx> wrote:
>>
>> Hi,
>>
>> We have ported our âVOViewsâ package from Torque to HTCondor. Iâve noticed three times now, that there are consistency issues. Basically it goes like this: if we look at what the CM says about how many dynamic slots there are with how many CPUs, this should agree with what a survey of the schedds says about the number of running jobs and cores occupied by them. If we then add in the number of offline slots, free slots (hanging around in the Partitionable slot waiting to be occupied) and slots held from running by the defrag daemon, this should equal the total capacity.
>>
>> This âsum ruleâ is what has been violated a few times. All three times have been moments where there is a lot of activity on the cluster; for example the most recent one, the cluster was opened back up after a downtime, so thousands of queued jobs suddenly found thousands of empty cores to try and occupy.
>>
>> I realized I could get a different ârunning jobâ view by collecting information on all the dynamic slots via condor_status. I did so, and compared that view to a simultaneous collection from the schedds - what I saw was that in the best case, they agreed; otherwise, it has always (always means the ten times I checked) been the case that the schedd has jobs that the CM does not, but never the other way around.
>>
>> Hypothesis : this must mean that some slots are âdoubly occupiedâ, which I checked, and indeed, in a few cases you could see that one of our CEs (Access Points) had a job from ATLAS in a particular dynamic slot, while a different access point claimed to have a job from LHCb in that exact same slot.
>>
>> Question: how fresh is the information supposed to be / guaranteed to be in the schedds and in the CM? I tried to find that information, as well as a description of whether one of those views was âholierâ than the other, I came up empty handed - anybody here know the answers?
>>
>> We have four access points btw.
>>
>> JT
>>
>>
>> _______________________________________________
>> HTCondor-users mailing list
>> To unsubscribe, send a message to htcondor-users-request@xxxxxxxxxxx with a
>> subject: Unsubscribe
>>
>> The archives can be found at: https://www-auth.cs.wisc.edu/lists/htcondor-users/
>
>
> _______________________________________________
> HTCondor-users mailing list
> To unsubscribe, send a message to htcondor-users-request@xxxxxxxxxxx with a
> subject: Unsubscribe
>
> The archives can be found at: https://www-auth.cs.wisc.edu/lists/htcondor-users/
>
> _______________________________________________
> HTCondor-users mailing list
> To unsubscribe, send a message to htcondor-users-request@xxxxxxxxxxx with a
> subject: Unsubscribe
>
> The archives can be found at: https://www-auth.cs.wisc.edu/lists/htcondor-users/