Hi Jason,
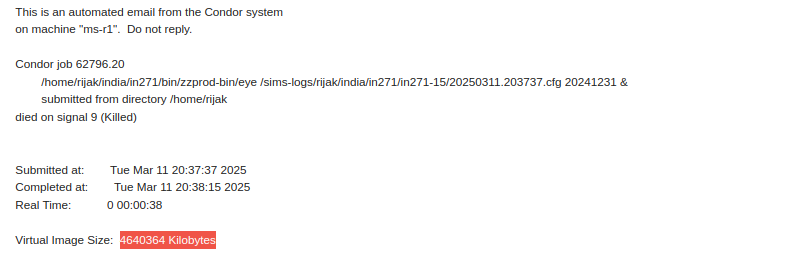
I did check the execution node logs. It was really out of memory that killed the jobs.
[2607562.133926] Memory cgroup out of memory: Killed process 827888 (eye) total-vm:8495504kB, anon-rss:8324680kB, file-rss:2816kB, shmem-rss:0kB, UID:5071 pgtables:16596kB oom_score_adj:800
So, the job was taking more than 8G of memory and got killed on signal 9 and it's fine since we have set max memory per job at 8G
But the email that the user received from condor showed only 4G virtual memory size.
condor_history -long 62796.20 | grep -i Resident
MemoryUsage = ((ResidentSetSize + 1023) / 1024)
ResidentSetSize = 4750000
ResidentSetSize_RAW = 4642028
MemoryUsage = ((ResidentSetSize + 1023) / 1024)
ResidentSetSize = 4750000
ResidentSetSize_RAW = 4642028
And below is mail from condor that the user received.
Can you please help as to why condor mail shows less amount of VM usage by the job.
Thanks,
Gagan
But the email
On Tue, Mar 4, 2025 at 8:18âPM Jason Patton via HTCondor-users <htcondor-users@xxxxxxxxxxx> wrote:
Hi Gagan,
What I can tell from the log is that something else (not condor) on the execution point sent your process a SIGKILL (signal 9)... maybe an out-of-memory killer, for example. Since condor didn't kill your job, it reports that the job exited of its own accord, and it likely transferred back the output and error files as they were in your job's scratch directory, so streaming is probably not necessary here. That your output and error files are blank suggests that your process did not produce any output before it was killed.
You might have to do some digging in other system logs on the execution point to figure out what sent your process the SIGKILL.
Jason
_______________________________________________On Mon, Mar 3, 2025 at 10:48âPM gagan tiwari <gagan.tiwari@xxxxxxxxxxxxxxxxxx> wrote:
Hi Jason,Thanks for your email.
Wanted to share with you couple of detail :-
Here is the reason of job crash ( Signal 9 )
condor_history -long 60990.13 | grep -i signal
ExitBySignal = true
ExitReason = "died on signal 9 (Killed)"
ExitSignal = 9
ToE = [ How = "OF_ITS_OWN_ACCORD"; Who = "itself"; When = 1740735423; ExitBySignal = true; HowCode = 0; ExitSignal = 9 ]
We do specify output and error log at the time of submission but didn't find any information in these files.
"executable": "$(bin)",
"arguments": "$(config)",
"output": "$(outfile)",
"error": "$(errfile)",
"log": "jobstatus.log",
Are these not sufficient ? Or do we need to specify "stream_error" in the submit file ?
And here is log from execute node slot on which this job was running :-
cat /var/log/condor/StarterLog.slot34 | grep -A25 60990.13
02/28/25 15:05:14 (pid:543127) Job 60990.13 set to execute immediately
02/28/25 15:05:15 (pid:543127) Starting a VANILLA universe job with ID: 60990.13
02/28/25 15:05:15 (pid:543127) Checking to see if htcondor is a writeable cgroup
02/28/25 15:05:15 (pid:543127) Cgroup memory/htcondor is useable
02/28/25 15:05:15 (pid:543127) Cgroup cpu,cpuacct/htcondor is useable
02/28/25 15:05:15 (pid:543127) Cgroup freezer/htcondor is useable
02/28/25 15:05:15 (pid:543127) Current mount, /, is shared.
02/28/25 15:05:15 (pid:543127) Current mount, /, is shared.
02/28/25 15:05:15 (pid:543127) IWD: /sims-logs/pol/YN/208
02/28/25 15:05:15 (pid:543127) Output file: /sims-logs/pol/YN/208/logs/20250205.stdout
02/28/25 15:05:15 (pid:543127) Error file: /sims-logs/pol/YN/208/logs/20250205.stderr
02/28/25 15:05:15 (pid:543127) Renice expr "0" evaluated to 0
02/28/25 15:05:15 (pid:543127) Running job as user pol
02/28/25 15:05:15 (pid:543127) About to exec /sims-logs/pol/YN/208/bin/bin.20250228.2/eye /sims-logs/pol/YN/208/logs/20250228.150859.cfg 20250205 &
02/28/25 15:05:15 (pid:543127) Cgroup memory/htcondor is useable
02/28/25 15:05:15 (pid:543127) Cgroup cpu,cpuacct/htcondor is useable
02/28/25 15:05:15 (pid:543127) Cgroup freezer/htcondor is useable
02/28/25 15:05:15 (pid:543157) Moved process 543157 to cgroup /sys/fs/cgroup/memory/htcondor/condor_var_lib_condor_execute_slot34@ms-s5
02/28/25 15:05:15 (pid:543157) Moved process 543157 to cgroup /sys/fs/cgroup/cpu,cpuacct/htcondor/condor_var_lib_condor_execute_slot34@ms-s5
02/28/25 15:05:15 (pid:543157) Moved process 543157 to cgroup /sys/fs/cgroup/freezer/htcondor/condor_var_lib_condor_execute_slot34@ms-s5
02/28/25 15:05:15 (pid:543157) Moved process 543157 to cgroup /sys/fs/cgroup/devices/htcondor/condor_var_lib_condor_execute_slot34@ms-s5
02/28/25 15:05:15 (pid:543127) Create_Process succeeded, pid=543157
02/28/25 15:07:03 (pid:543127) Process exited, pid=543157, signal=9
02/28/25 15:07:03 (pid:543127) Failed to write ToE tag to .job.ad file (13): Permission denied
02/28/25 15:07:03 (pid:543127) All jobs have exited... starter exiting
02/28/25 15:07:03 (pid:543127) **** condor_starter (condor_STARTER) pid 543127 EXITING WITH STATUS 0
02/28/25 15:36:08 (pid:543847) ******************************************************
Can you please help figure out what could be the reason for the job crash with signal 9 with the above detail.
Thanks,Gagan
On Mon, Mar 3, 2025 at 8:38âPM Jason Patton via HTCondor-users <htcondor-users@xxxxxxxxxxx> wrote:
Hi Gagan,
In /var/log/condor on the execution point, the StarterLog for the slot that the job ran on might have some more information on what happened, particularly if it had something to do with condor. If the error is not condor related, one thing you can try when submitting the job, particularly if you have reason to expect it to fail, is to set stream_ouptut and stream_error in your submit file to stream the job's stdout and stderr back to the access point, though you will probably want to limit this to only a couple jobs as it can stress the network and disk of the access point: https://htcondor.readthedocs.io/en/latest/man-pages/condor_submit.html#stream_error
Jason
_______________________________________________On Fri, Feb 28, 2025 at 8:49âAM gagan tiwari <gagan.tiwari@xxxxxxxxxxxxxxxxxx> wrote:
Hi Guys,_______________________________________________At times , jobs running on exec nodes crashed with Signal 9 error. But this is a generic message and we don't know exactly what went wrong with the jobs.Is there any setting in condor which can be tweaked to provide detailed information about what exactly happened?
Thanks,Gagan
HTCondor-users mailing list
To unsubscribe, send a message to htcondor-users-request@xxxxxxxxxxx with a
subject: Unsubscribe
Join us in June at Throughput Computing 25: https://urldefense.com/v3/__https://osg-htc.org/htc25__;!!Mak6IKo!PFiVWScAJOMtq2okmjp_-ajHBiC5_bzkouhme7wn3DIKu44q0KeT0PQ9Jy8VgsyMoRma3jmG5X06Rw-oaLOUOrDn42hVSXwH$
The archives can be found at: https://www-auth.cs.wisc.edu/lists/htcondor-users/
HTCondor-users mailing list
To unsubscribe, send a message to htcondor-users-request@xxxxxxxxxxx with a
subject: Unsubscribe
Join us in June at Throughput Computing 25: https://osg-htc.org/htc25
The archives can be found at: https://www-auth.cs.wisc.edu/lists/htcondor-users/
HTCondor-users mailing list
To unsubscribe, send a message to htcondor-users-request@xxxxxxxxxxx with a
subject: Unsubscribe
Join us in June at Throughput Computing 25: https://osg-htc.org/htc25
The archives can be found at: https://www-auth.cs.wisc.edu/lists/htcondor-users/
_______________________________________________ HTCondor-users mailing list To unsubscribe, send a message to htcondor-users-request@xxxxxxxxxxx with a subject: Unsubscribe Join us in June at Throughput Computing 25: https://osg-htc.org/htc25 The archives can be found at: https://www-auth.cs.wisc.edu/lists/htcondor-users/