So, starting with condor 8.4.4 (8.2.10 previously, that did not
exhibit this issue), and now continuing in 8.4.6 (we skipped over
8.4.5), we have an odd situation. Every 5 minutes, from 2 separate
hosts (but not on the same minute) I do a condor_status and condor_q
pair to dump information from our gatekeepers. The main gatekeeper
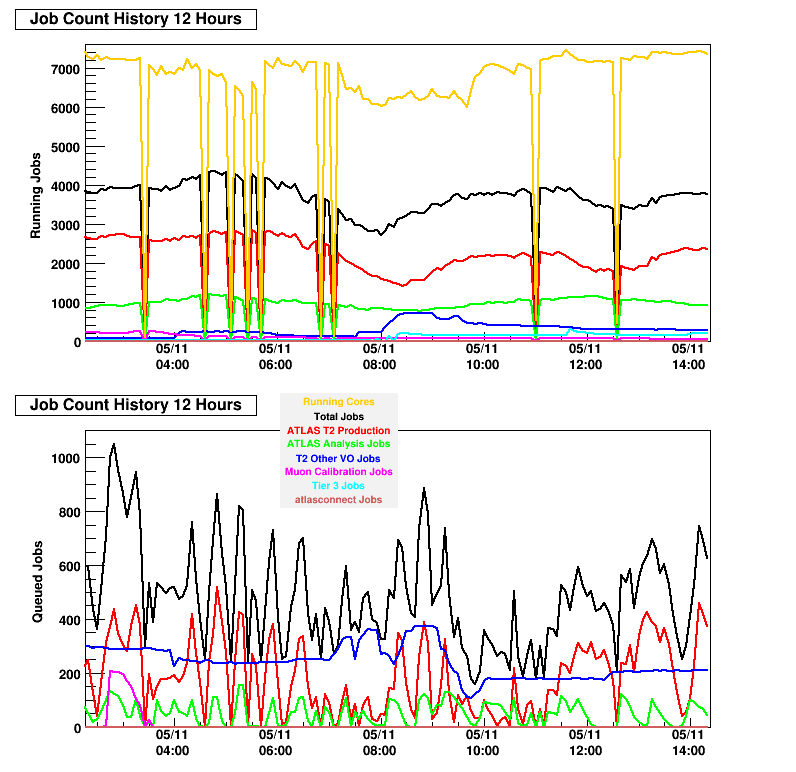
typically has ~4200 jobs running on ~7600 cores (a single-core andÂ
multi-core job mix). After approximately 1 week, that gatekeeper
begins to have problems responding to these queries, from either
itself of the other host. See the attached image, and note the
spikes driving down towards zero. This can be resolved by a
"service condor restart" on the main gatekeeper, until another week
or so passes by at which time the problem again asserts.
Has anyone else seen this issue? Any suggestions? Seems perhaps
like a memory leak, or....
The gatekeeper is a VM with 16GB of RAM, 4 cores, and access to a
shared pair of 10Gb NICs. There was no noticeable change in Ganglia
load_one around the time of the HTCondor restart, or for that matter
no other metric seemed "off".
Thanks,
bob
|